Summarize
- A module runs in kernel space, whereas applications run in user space. This concept is at the base of operating systems theory
- One way in which kernel programming differs greatly from conventional application
programming is the issue of concurrency
- Kernel code cannot do floating point arithmetic
Outline
- The Hello World Module
- Kernel Modules Versus Applications
- User Space and Kernel Space
- Concurrency in the Kernel
- The Current Process
- A Few Other Details
The Hello World Module
// KOBJ File: hello.ko
#include <linux/init.h>
#include <linux/module.h>
MODULE_LICENSE("Dual BSD/GPL");
static int hello_init(void)
{
printk(KERN_ALERT "Hello, world\n");
return 0;
}
static void hello_exit(void)
{
printk(KERN_ALERT "Goodbye, cruel world\n");
}
module_init(hello_init);
module_exit(hello_exit);
應該不太需要解釋,見操作:
insmod ./hello.ko
Hello, world
root# rmmod hello
Goodbye cruel world
Kernel Modules Versus Applications
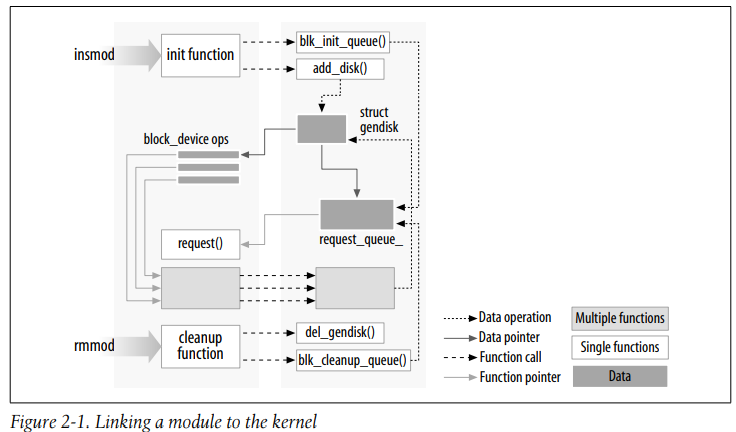
- This kind of approach to programming is similar to eventdriven programming, but while not all applications are event-driven, each and every kernel module is
- As a programmer, you know that an application can call functions it doesn’t define:
- the linking stage resolves external references using the appropriate library of functions
- printf is one of those callable functions and is defined in libc
- A module, on the other hand, is linked only to the kernel, and the only functions it can call are the ones exported by the kernel; there are no libraries to link to
- The printk function used in hello.c earlier, for example, is the version of printf defined within the kernel and exported to modules
User Space and Kernel Space
A module runs in kernel space, whereas applications run in user space. This concept is at the base of operating systems theory
- All current processors have at least two protection levels, and some, like the x86
family, have more levels; when several levels exist, the highest and lowest levels are
used
- Under Unix, the kernel executes in the highest level (also called supervisor
mode), where everything is allowed, whereas applications execute in the lowest level
(the so-called user mode), where the processor regulates direct access to hardware
and unauthorized access to memory
- These terms encompass not only the different privilege levels inherent in the two modes, but also the fact that each mode can have its own memory mapping—its own address
space—as well
- The role of a module is to extend kernel functionality; modularized code runs in kernel space
- Usually a driver performs both the tasks outlined previously: some functions in the module are executed as part of system calls, and some are in charge of
interrupt handling
Concurrency in the Kernel
One way in which kernel programming differs greatly from conventional application
programming is the issue of concurrency
- As a result, Linux kernel code, including driver code, must be reentrant
- it must be capable of running in more than one context at the same time. Data structures must be carefully designed to keep multiple threads of execution separate, and the code
must take care to access shared data in ways that prevent corruption of the data
The Current Process
- most actions performed by the kernel are done on behalf of a specific process
- Kernel code can refer to the current process by accessing the global item current, defined in <asm/current.h>, which yields a pointer to struct task_struct, defined by <linux/sched.h>
- The current pointer refers to the process that is currently executing. During the execution of a system call, such as open or read, the current process is the one that invoked the call
The following statement prints the process ID and the command name of the current process by accessing certain fields in struct task_struct:
printk(KERN_INFO "The process is \"%s\" (pid %i)\n", current->comm, current->pid);
A Few Other Details
as you dig into the kernel, the following issues should be kept in mind:
- Applications are laid out in virtual memory with a very large stack area. The stack, of course, is used to hold the function call history and all automatic variables created by currently active functions
- The kernel, instead, has a very small stack; it can be as small as a single, 4096-byte page. Your functions must share that stack with the entire kernel-space call chain
- Thus, it is never a good idea to declare large automatic variables; if you need larger structures, you should allocate them dynamically at call time
as you look at the kernel API, you will encounter function names starting with
a double underscore (__)
- Functions so marked are generally a low-level component of the interface and should be used with caution
- Essentially, the double underscore says to the programmer: “If you call this function, be sure you know what you are doing.”
Kernel code cannot do floating point arithmetic
- Enabling floating point would require that the kernel save and restore the floating point processor’s state on each entry to, and exit from, kernel space—at least, on some architectures
- The extra overhead is not worthwhile
Reference
-
LDD3

